Unicode Identifiers in 2.5 KiB
Recently I had some free time and decided to partake in one of my favorite programming exercises: where I take a small, well-defined problem and put way more effort into it than is necessary to see how well I can solve it. This time I wanted to see how well I could implement Unicode Standard Annex #31, which lays out the rules for which characters may start or be a part of identifiers in programming languages and other contexts.
As a point of reference, I had my eye on the Rust crate
unicode-id-start, which claims to be a faster, smaller
alternative to other crates like unicode-id, unicode-xid, and ucd-trie.
Another reason was that despite using less static storage space than its peers,
unicode-id-start embeds 10,396 bytes of tables for such a seemingly simple
bit of functionality. While many would agree that 10,396 bytes isn’t an
unreasonable amount of space, I wanted to challenge the assumption that it’s
“good enough” and see if I could do better, and if so what the tradeoffs would
be. Thus, before doing any research I set my sights on finding a solution which
used under 5 KiB of space without sacrificing performance. I set the initial
target high to force aggressive tradeoffs without yet knowing whether it was
realistic.
If you want to follow along, the code lives on GitHub in the repository
aeldidi/unicode-id-trie-rle, in the commit
1d03d8dae8970e926ae23c9cf4a7e5e38ca4f645.
The Problem
Since Unicode has so many characters, how can someone developing a programming language decide which of the characters are valid in identifiers? Traditionally languages would have just only allowed ASCII or have some whitelist, but Unicode Standard Annex #31 (from now on referred to as UAX #31) provides a way to programmatically determine which characters are valid in various positions in identifiers for a given Unicode version. This means that programming languages and other similar use-cases can nearly transparently support international names without needing to ensure they’ve accounted for every problematic character.
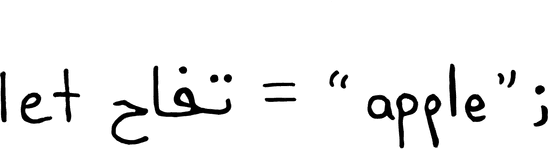
An identifier as defined by
UAX #31 is any string whose
first codepoint has the XID_Start property, and whose remaining characters
have the XID_Continue property. These properties are bits of metadata
associated with each codepoint, defined in a file called
DerivedCoreProperties.txt which is distributed with
each new unicode version.
What that means is that the problem of “determining if a string is a valid
codepoint” reduces down to efficiently mapping each codepoint (which are 21-bit
integers) to two bits of state, one for each relevant property. With
1,114,112 total codepoints, it would take
The Baseline: Dense Table
Before getting into any real optimization, it’s important to have a reasonable starting point to get a feeling for what “highly optimized” looks like for this problem. In this case a densely-packed lookup table can serve this need well, as it would demonstrate where the inefficiencies lie and give a better look at the shape of the data.
To generate the table I wrote a build.rs which, at compile time, parses the
DerivedCoreProperties.txt file to get every codepoint’s properties into a
BTreeMap (Rust speak for “hashmap ordered by key”) mapping each codepoint to
its two bit state value. The format of DerivedCoreProperties.txt is simple:
Each non-empty line specifies a range of codepoints and the property that
applies to that range, separated by a semicolon, with an optional trailing
comment.
It’s so simple, that the entire main parsing loop is shown below:
loop {
buf.clear();
if reader.read_line(&mut buf)? == 0 {
break;
}
if let Some(comment_start) = buf.find('#') {
buf.truncate(comment_start);
}
let trimmed = buf.trim();
if trimmed.is_empty() {
continue;
}
let Some((codepoint_range, prop_name)) = trimmed.split_once(';')
else {
return Err(Error::MissingDelimiter(trimmed.to_string()));
};
let prop_name = prop_name.trim();
let (start_range, end_range) = parse_range(codepoint_range)?;
for cp in start_range..=end_range {
if let Some(x) = result.get_mut(&cp) {
x.insert(prop_name.to_string());
} else {
result.insert(cp, HashSet::from_iter([prop_name.to_string()]));
}
}
}With that, the table can be built by filtering out all the properties which aren’t relevant, and mapping the ones that are into a two bit value:
let parsed = parsed
.iter()
.filter(|(_, v)| v.contains("XID_Start") || v.contains("XID_Continue"))
.map(|(k, v)| {
(
*k,
v.iter()
.map(|x| {
if x.contains("XID_Start") {
1 << 0
} else if x.contains("XID_Continue") {
1 << 1
} else {
0
}
})
.fold(0, |acc, x| acc | x),
)
})
.collect::<BTreeMap<u32, u64>>();The table then just lays these values out sequentially:
let mut buffer = Vec::new();
let mut i = 0;
while i <= MAX_CODEPOINT {
let mut value: u64 = 0;
let mut limit: u32 = 31;
if i + limit > MAX_CODEPOINT {
limit = MAX_CODEPOINT - 1;
}
for j in 0..=limit {
let c = i + j;
value |= parsed.get(&c).unwrap_or(&0) << j * 2;
}
buffer.push(value);
i += 32;
}This takes up 34,816 bytes, which could be sufficient to a use case which
didn’t need to optimize for size. This is why it’s always good to have a
baseline measurement. I’ve set up the benchmarks to test various input sizes,
and various percentages of ASCII input, so we can see how it performs when
compared to unicode-id-start:
The baseline does a simple memory lookup, and unicode-id-start uses a
specialized data structure for retrieval which also amounts to a couple of
memory lookups, so as expected the baseline is slightly ahead in most cases.
The next step is to find out how to optimize the storage. Effective
optimization requires knowing what the shape of the data is and the access
patterns it should be able to support efficiently. In our case lookups are
essentially random access with a strong bias towards the ASCII range, so the
data structure should make storing and retrieving that kind of data easy. To
make the structure of the data obvious, I generated a visualization of the
entire Unicode range as dense grid of pixels, representing each codepoint in
order. Pixels are colored yellow if they have the XID_Continue property, and
blue if they have the XID_Start property (also blue if they have both since
XID_Continue is a subset of XID_Start).

Looking at this shows that the vast majority of the 21-bit codepoint
space has neither XID_Start nor XID_Continue, and that most codepoints
which do are in long runs where each consecutive one has the same values as the
last. Noticing this was what led me to the first optimization.
Run-Length Encoding and Indexing
My first instinct was to run length encode the data stored in the table, since there are so many consecutive codepoints with the same value (represented as long horizontal lines of the same color in the visualization). Run length encoding is a technique which represents the data as pairs of “run length” and “value”, where the “value” is repeated “run length” times in the source.
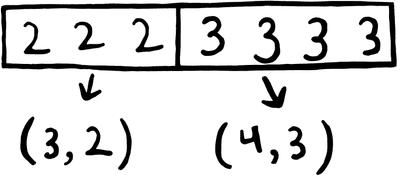
This greatly reduces the size of the table, but requires each lookup to start at the beginning and scan linearly, because the decoder can’t know where a given codepoint is in the table in advance. Fortunately, the lookup can be sped up by using the most significant N bits of the input codepoint as an index into a table that records the starting position of each corresponding codepoint range. That way the decoder doesn’t have to linearly scan the entire table, just a small portion of it starting somewhere close by to the result. This only adds a little complexity to the lookup function in the form of an additional shift and lookup before the run-length decoding loop:
#[inline]
fn block_index(block: usize) -> usize {
debug_assert!(block < BLOCK_COUNT);
let bit_offset = (block as u32) * INDEX_BITS;
let byte = (bit_offset >> 3) as usize;
let shift = (bit_offset & 7) as u32;
let chunk = u32::from_le_bytes([
BLOCK_INDEX[byte],
BLOCK_INDEX[byte + 1],
BLOCK_INDEX[byte + 2],
BLOCK_INDEX[byte + 3],
]);
((chunk >> shift) & INDEX_MASK) as usize
}After some measuring I found using an 11 bit index gave the best balance between size and performance. The resulting static table size was 5676 bytes, a significant reduction. The only question is: how much slower is the decoder?
For a lot of use cases this might be good enough, however it’s still slower than the status quo in pretty much all situations, with no obvious path to improving it. Simply adding another index could help, but would come at the cost of storage space, to the extent that we would be far from the 5 KiB goal I set at the beginning.
While the index helps, the implementation is still limited by the fact that we treat the actual data as an opaque run-length encoded blob. Further improvements could be made by using run-length encoding alongside a better structure which would allow indexing more data in less space.
Trie
It was at this point that I realized that I had essentially just derived the intuition behind using a trie data structure for this problem as most other implementations do. A trie is a tree data structure where a value’s key is not stored alongside the value, but rather is determined by the value’s position in the tree. This is similar to how the index in our version stores the high bits of each codepoint, with the difference that a trie would then only store the low bits at the leaf nodes of the tree. Unfortunately our implementation can’t do this directly while still keeping the run-length encoding scheme, but it can use the same structure to good effect.
By splitting the input range into blocks and only run-length encoding within those blocks, our implementation can still use the trie structure for lookups without adding a significant amount of space. The trie would store these blocks at the leaf nodes, and only store the low bits by making the run-length encoding values relative to the block’s starting codepoint value.
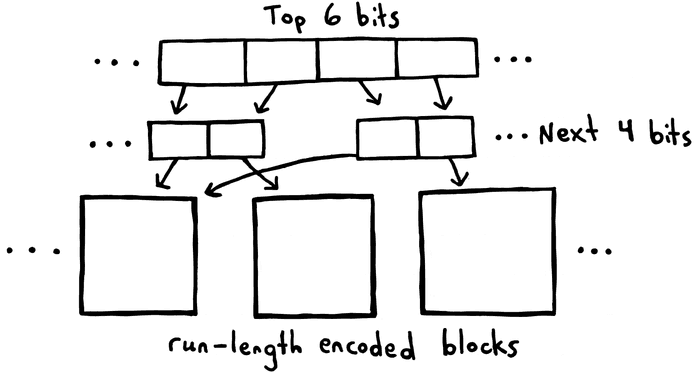
Another optimization this allows is block-level deduplication. Since each block only stores offsets relative to the beginning value and most of the input range is empty, there will be many identical blocks at the second and bottom level of the trie, which we can avoid storing. We would just make each codepoint mapping to an identical block point to one instance of that run-length encoded pattern of data. This allows the implementation to avoid storing any indexing structures for long stretches of identical data.
Of course nothing comes for free, and there are a couple of costs when switching to this design.
Firstly, a trie is a multi-level data structure, which means it will have to add more static data to store the various levels of the trie. It also loses the ability to run-length encode globally. Rather than representing a string of 20,000 identical bytes as one run-length encoded pair, it can now at best represent it as 3 pairs unless it happens to fall on a byte boundary aligned with our block size. It also adds some code to the decoder and code generator, which now need to reason about a multi-leveled tree and deduplication.
Luckily the code is still quite readable. I got away with only needing two tiny helper functions in the decoder:
#[inline]
fn load_leaf(idx: usize) -> Leaf {
debug_assert!(idx + 1 < LEAF_OFFSETS.len());
let start = LEAF_OFFSETS[idx] as usize;
let end = LEAF_OFFSETS[idx + 1] as usize;
Leaf {
offset: start,
len: end - start,
}
}
#[inline]
fn leaf_value(leaf: Leaf, offset: u16) -> UnicodeIdentifierClass {
debug_assert!(leaf.len >= 2);
let runs = &LEAF_RUN_STARTS[leaf.offset..leaf.offset + leaf.len];
let values = &LEAF_RUN_VALUES[leaf.offset..leaf.offset + leaf.len];
// runs are ascending with runs[0] == 0 and a sentinel at the end.
let idx = runs.partition_point(|&start| start <= offset);
UnicodeIdentifierClass(values[idx.saturating_sub(1)])
}and some bit twiddling in the lookup function which uses them:
/// Returns whether the codepoint specified has the properties `ID_Start`,
/// `XID_Start` or the properties `ID_Continue` or `XID_Continue`.
#[inline]
pub fn unicode_identifier_class(cp: char) -> UnicodeIdentifierClass {
// ASCII fast path via table to avoid unpredictable branches.
if (cp as u32) < START_CODEPOINT {
return UnicodeIdentifierClass(ASCII_TABLE[cp as usize]);
}
if (cp as u32) >= 0x100000 {
return UnicodeIdentifierClass(IDENTIFIER_OTHER);
}
let cp = cp as u32;
let block = cp >> SHIFT;
debug_assert!(block < BLOCK_COUNT as u32);
let top = (block >> LOWER_BITS) as usize;
let bottom = (block & LOWER_MASK) as usize;
let level2_idx = LEVEL1_TABLE[top] as usize;
let leaf_idx = LEVEL2_TABLES[level2_idx * LOWER_SIZE + bottom] as usize;
let leaf = load_leaf(leaf_idx);
let offset = (cp & BLOCK_MASK) as u16;
leaf_value(leaf, offset)
}The code generator ended up quite relatively concise too, given that it’s doing
some heavy lifting. One thing I did to try to reduce the complexity a bit was
to use 10 bits for the index instead of 11. Since the entire codepoint space is
21 bits in size (the maximum codepoint is 0x10ffff), and all codepoints past
U+100000 can be skipped (they are all either private use or non-characters),
this left exactly 1024 blocks each containing 1024 codepoints, which leaves no
wasted bits.
To encode this, the build script first globally run-length encodes the data including a sentinel at the end:
fn build_runs(table: &[u8]) -> Vec<(u32, u8)> {
let mut runs = Vec::with_capacity(1024);
let end_cp = MAX_CODEPOINT + 1; // sentinel run start
let mut run_start = START_CODEPOINT;
let mut current = table[run_start as usize];
for cp in (START_CODEPOINT + 1)..=end_cp {
let value = if cp <= MAX_CODEPOINT {
table[cp as usize]
} else {
0
};
if value != current {
runs.push((run_start, current));
run_start = cp;
current = value;
}
}
runs.push((run_start, current));
if runs.last().map_or(true, |(s, _)| *s != end_cp) {
runs.push((end_cp, 0));
}
runs
}then splits it into blocks and uses a hashmap to deduplicate the data “for free” as it’s processed, rather than doing it after the fact:
let mut leaf_runs: Vec<(u16, u8)> = Vec::new();
let mut leaf_offsets: Vec<u16> = Vec::new(); // start index into leaf_runs
let mut leaf_map: HashMap<Vec<(u16, u8)>, u16> = HashMap::new();
let mut block_to_leaf = Vec::with_capacity(block_count as usize);
for block in 0..block_count {
let block_start = block << SHIFT;
let block_end = ((block + 1) << SHIFT).min(MAX_CODEPOINT + 1);
let mut idx = block_index[block as usize];
let mut local_runs = Vec::new();
loop {
let (start, value) = runs[idx];
let next_start = runs[idx + 1].0;
if next_start <= block_start {
idx += 1;
continue;
}
let run_from = start.max(block_start);
if run_from < block_end {
local_runs.push(((run_from - block_start) as u16, value));
}
if next_start >= block_end {
break;
}
idx += 1;
}
local_runs.push(((block_end - block_start) as u16, 0));
let leaf_id = if let Some(&id) = leaf_map.get(&local_runs) {
id
} else {
let id =
u16::try_from(leaf_map.len()).expect("leaf count fits in u16");
let start = leaf_runs.len();
leaf_offsets.push(start as u16);
leaf_runs.extend_from_slice(&local_runs);
leaf_map.insert(local_runs.clone(), id);
id
};
block_to_leaf.push(leaf_id);
}
leaf_offsets.push(leaf_runs.len() as u16); // sentinel for computing leaf lengthsThe sentinel at the end is meant to help the decoder, since it allows it to avoid doing bounds checks. All in all, this implementation uses 6603 bytes, which is slightly worse than the run-length encoded version, but if all went well, should perform much better:
While slower than I expected on some workloads, I would imagine that in most real-world scenarios it should outperform the other implementations. This is because since the most common programming language identifiers (i.e language keywords) tend to be shorter in length and in English, which is contained within the ASCII range. Shorter, predominantly ASCII inputs are exactly where my implementation tends to outperform, and thus shouldn’t be an issue. In the end I’m not surprised that I ended up with such a similar structure to most other implementations, since the fastest solutions often come from clean structure and measurement, not heroic micro-optimizations.
At this point, I’m essentially done, since It should be clear that the implementation is coming pretty close to “as good as I can do” without a complete change in direction, and that any further optimizations would likely come at the cost of more performance or more storage space. I didn’t quite reach my initial goal of staying under 5 KiB, but I think I came close enough.
There was just one question that kept nagging me: How small could we make this if we didn’t care about how it performed?
Bonus: “Unicode Identifiers in 2.5 KiB”
For the sake of this challenge, I decided to exclude any kind of general purpose compression. I felt it would’ve been against the spirit of problem-solving to just use zstd on our run-length encoded version and declare victory. In this section, I won’t be benchmarking at each step, since I’m not concerned with performance anymore. I’ll still benchmark the final result against the others to give a frame of reference for what needed to be sacrificed for these last savings.
With that being said, it makes the most sense to start with the run-length encoded implementation, minus the index. This was the smallest one yet and is the least complicated. I have three techniques I want to take advantage of to try and shrink this: variable-length encoding the various integer values stored, delta encoding instead of run-length encoding, and bit-packing the entire thing.
Variable-length Encoding Integers
It makes sense to start by variable-length encoding the integers. The difference between this and previously is that instead of each integer value stored taking up a fixed amount of data (the run-length encoding implementation uses 24 bits), each integer is split up into 7 bit chunks with the most significant bit being used to flag whether the integer continues in the next byte. Specifically, if the most significant bit is set, that means the integer continues. We stop decoding once the most significant bit of a byte is unset.
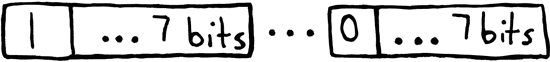
This means that smaller integers will use fewer bits total, and larger integers
will use at most 4 bytes (1 more than we previously did). If most integers in
the data set are small, this will be a net positive. In our case, most values
are contained in a couple of high-density areas, and thus most runs should be
small enough that this saves space. To demonstrate, notice how while a number
which uses seven bits can just be written as a single byte which is equal to
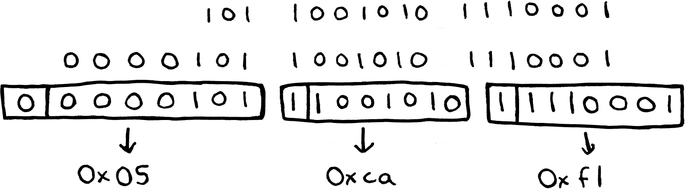
the number, whereas a larger number like 91505 (or 0x16571) would be encoded
in 3 bytes, and written as 0xf1, 0xca, and 0x05:
This format of encoding integers is called LEB128, and is used in a number of places, like debug information, WebAssembly, and Protocol Buffers (although Protocol Buffers handle signed integers different than most implementations). The encoder for this format is quite small, only being a handful of lines of code:
fn emit_leb128(mut x: u32, buffer: &mut Vec<u8>) {
loop {
let mut byte = (x & 0x7f) as u8;
x >>= 7;
if x != 0 {
byte |= 0x80;
}
emit_bits(8, byte as u64, buffer);
if x == 0 {
break;
}
}
}and the decoder is similarly small:
fn read_leb128(&mut self) -> u32 {
let mut result: u32 = 0;
let mut shift = 0;
loop {
let byte = self.read_bits(8);
result |= ((byte & 0x7f) as u32) << shift;
if byte & 0x80 == 0 {
break;
}
shift += 7;
}
result
}but by introducing a loop into the hot path, we can expect a noticable hit to performance.
Sparse-optimized Run-length Encoding
The next thing I did was to modify the compression algorithm slightly to better suit our input data. While run-length encoding does well to reduce the actual amount of data we need to store, it doesn’t address the fact that the data is dominated by one specific value of data, that being 0. Ideally we would just not store those at all, and just have those bytes be implicit when a value isn’t provided. To get as close as possible to that ideal, I decided to only store nonzero runs of data, and include with them an extra integer (which I called the “offset”) which represents the number of codepoints in between the previous and current runs which have zero values.
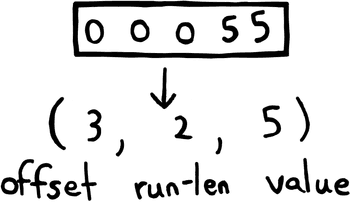
What this does is effectively reduce the size of 0-value runs to be the size of a single LEB128 encoded integer. When the data is sparsely packed (which our data is) the offset is nearly always a single byte. Throughout the entire data set, this results in a nearly 2x saving when combined with the final optimization. I previously called this modified run-length encoding scheme “delta encoding”, but later realized that delta encoding actually refers to a completely different compression scheme used by git (you can even see this in earlier commits in the git repo which this article references).
The final source of waste to eliminate relates to the 2-bit value we store along with each nonzero run. We’re already encoding the integers as small as we reasonably can, and there isn’t any other structures we could easily pack the two value bits into, so we seem to be left with an unavoidable 6 bits of waste in the last byte of each run.

Bit-Packing
It might seem silly to keep those bits at first since they don’t actually store any information, but they serve a greater purpose: Ultimately, the decoder needs to run on some kind of CPU, which (nearly) all address memory in units which are multiples of 8 bits. This is the entire reason we have abstractions like “bytes”, and choosing not fit our data within these abstractions is not really an option.
This means that when dealing with data not aligned to 8-bit boundaries (like we plan to do) the decoder is forced to shuffle around bits in memory to fit into bytes before being able to do any processing. The code for this ends up implementing small primitives for reading and writing memory in software, rather than relying on the CPU’s native ability to do so.
This all relies on a small data structure which keeps track of the decoder’s bit position within a given buffer:
struct BitReader<const N: usize> {
buffer: [u8; N],
current: usize,
current_bitpos: u8,
}and implements a read_bits method which we can use whenever we might normally
read from memory:
fn read_bits(&mut self, n: u8) -> u8 {
assert!(n > 0 && n <= 8);
let mut result = 0;
let mut filled = 0;
assert!(self.current < self.buffer.len());
while filled < n {
let byte = self.buffer[self.current];
let available = 8 - self.current_bitpos;
let mut take = n - filled;
if take > available {
take = available;
}
// `take` can be 8, so compute the mask using a wider type to avoid
// shifting `1u8` by 8 bits, which would overflow.
let mask = ((1u32 << (take as u32)) - 1) as u8;
let part = (byte >> self.current_bitpos) & mask;
result |= part << filled;
self.current_bitpos += take;
if self.current_bitpos == 8 {
self.current_bitpos = 0;
self.current += 1;
}
filled += take;
}
result
}While it may may not seem like a lot of code, you have to realize that
read_bits is replacing this code:
let byte = array[i];Doing so completely removes the ability of the CPU to efficiently do anything, since this adds branches and loops into the hot path which mess with the branch predictor. The upside is that each run should now be laid out tightly in the available memory, and no more “wasted space” should still be present:
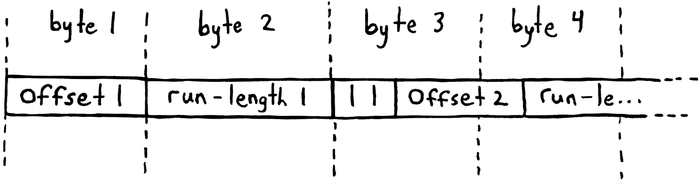
Results
After all this hard work, the static table now only takes up 2487 bytes, which is less than half of the size of the flagship implementation, and the namesake of the article. The various size optimizations work really well together to exploit the shape of the data and ensure that there is essentially no wasted space. For the curoius, here are the benchmark results:
As expected it’s significantly slower than the others, to the extent that you can’t really see the other implementations anymore in the graph. This could still be a valid tradeoff, but only in a use case which is extremely constrained by static storage size at all costs. I would be surprised if there was such a use case which needed to validate Unicode identifiers, but I thought I’d mention it for completeness’ sake.
Conclusion
While I had fun, I didn’t want to keep this exclusive to people using Rust, so
I ported the unicode-id-trie-rle implementation for both Go and C as well.
Those two are both in the repository associated with this article. The C
version is just a single .c file along with a code generator which can be
compiled as one unit:
cc -std=c11 -o generate generate.cand generates the data file like so:
./generate path/to/DerivedCoreProperties.txt > unicode_data.hI included a pre-generated unicode_data.h which means you don’t have to do
this, but it’s probably a good idea to have your build system automate this in
case you ever want to upgrade to a new Unicode version by swapping out the
DerivedCoreProperties.txt file.
The Go version can be used by just importing from the Github repository, and
similarly commits a pre-generated file which is run using go generate, like
so:
go generate ./...Of course, the Rust version is also available on crates.io as
unicode-id-trie-rle if you
want to use it. Overall I’m very satisfied with this experiment, as I got to
explore different tradeoffs and came to what I would consider a superior
solution to what the state of the art seemed to be (at least for my use cases).